
Chapter 3: Attacking AI Agents
Goal: enumerate agent services, extract their internal configurations, hijack their objectives, poison their data sources, and persist across sessions.
Single-Agent Architecture
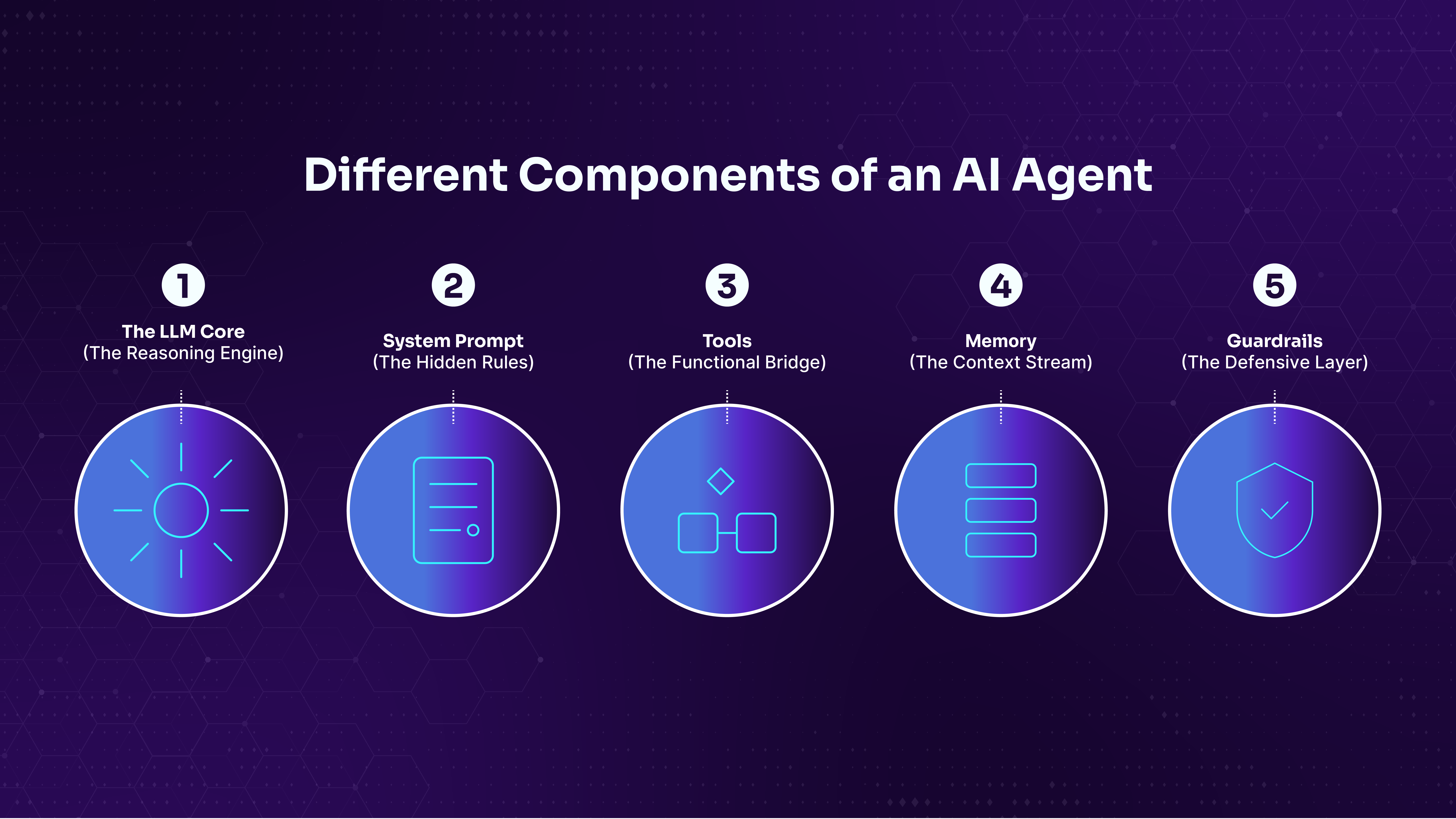
Core components:
The LLM core is the reasoning engine. It processes everything as tokens: system prompts, user input, tool outputs, and memory. It doesn't distinguish between these sources. They all arrive in the same token stream, and this lack of trust boundaries is the foundation of every attack in this Module.
The system prompt is a set of hidden instructions that define the agent's identity, rules, restrictions, available tools, and behavioral boundaries. System prompts often contain sensitive information: internal URLs, database credentials, API keys, filter keyword lists, and security rules. They're hidden from the user but visible to the LLM, and as we'll see, extracting them is often the first step in an engagement.
Tools give the agent capabilities beyond text generation. A tool might read files from the filesystem, fetch a web page, query a database, or call an internal API. The agent decides which tools to call based on the user's request and the system prompt's configuration. Tools are what make agents dangerous to attack. They bridge the gap between "the agent said something it shouldn't" and "the agent accessed something it shouldn't."
Memory comes in two forms. Short-term memory is the conversation history within a session, where the agent remembers what you said earlier in the same chat. Long-term memory persists across sessions, stored in databases or knowledge bases. Both types are fed back into the LLM's context, and both can be poisoned.
Guardrails are the defensive layer: input filters that block known injection phrases, output scanners that prevent credential leakage, content scanners that check uploaded documents, and behavioral monitors that detect goal hijacking. In practice, guardrails are pattern-matchers, and pattern-matchers have blind spots. Every walkthrough in this Module identifies the specific blind spot in each guardrail we encounter.
Reasoning Loop: Each step can be an injection point.
User Message --> LLM Thinks --> Chooses Action --> Executes Tool
^ |
+------------ Observation fed back ---------------+
...repeats...
--> Final Answer --> Output Filters --> Response
Attack surface
Every channel the agent reads from is a potential input vector, and every channel it writes to is a potential output for exfiltration.
| Input Channel | Description | Attack Type |
|---|---|---|
| Direct input | User messages to the agent | Direct prompt injection |
| Ingested data | Documents, web pages, code files | Indirect prompt injection |
| Tool responses | Data returned from tool calls | Tool response poisoning |
| Memory retrieval | Data from conversation history or persistent stores | Memory poisoning |
| Output Channel | Description | Abuse Type |
|---|---|---|
| Text responses | The agent's reply to the user | Data exfiltration |
| Tool invocations | File writes, API calls, emails | Unauthorized actions |
| Memory writes | Data stored for future retrieval | Persistent backdoors |
The most powerful attacks combine an input channel with an output channel.
Example: poison a document (input: ingested data) to make the agent leak its credentials in the response (output: text response). Or write to a knowledge base (output: memory write) so that future users get directed to a phishing page (input: memory retrieval). The combination is what creates real operational impact.
Enumerate-Attack-Detect-Evade Cycle
Enumerate -> Attack -> Detect -> Evade -> Confirm