
New Page
Scenario
Target: NovaTech
Assessment Type: Grey Box assessment focused on their AI infratructure
Access: Network access to a segment hosting several AI-facing services
System
- A public-facing customer assistant with HTTP API access
- An internal GitLab instance hosting AI project repositories
- Two knowledge base endpoints backed by RAG pipelines
- A SIEM server collecting AI interaction logs
Attack Surface
Not monolithic, consisting of multiple layers.
The Orchestration Layer coordinates how requests flow through the system. Frameworks like LangChain, LangGraph, CrewAI, and AutoGen manage prompt construction, context windows, and multi-step reasoning. Each framework has characteristic behaviors and error messages that can be fingerprinted through interaction. In practice, these frameworks often embed the components shown in the diagram. RAG logic, tool definitions, and inference client calls are typically integrated within the orchestration code rather than existing as separate services.
RAG: Fetch relevant context from vector databases before sending prompts to the model. While often implemented within orchestration frameworks, RAG functionality has distinct enumerable parameters.
Agent Tools: Expose capabilities through protocols like Model Context Protocol (MCP) (more about MCP) and includes permission boundaries that can be tested.
External Integration: Connect the AI to databases, file systems, and other agents via protocols like Google's Agent-to-Agent.
Inference server: Host the actual model and handles tokenization, generation, and response formatting. Such as Ollama, vLLM, TGI.
Reconnaissance Methods
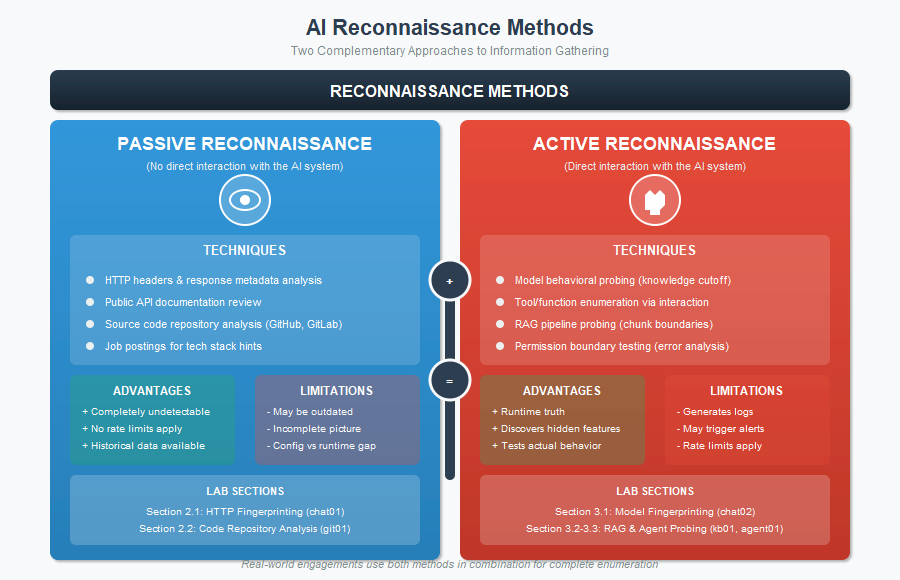
Passive:
- Analyze HTTP headers
- Review public API documentation
- Exam source code repo
- Mine job posts for tech stack hints
- More+
Active:
- Probe model knowledge cutoffs
- Tool enumeration
- RAG pipeline analysis via Chunk boundary detection
- Permission testing
- More+
Model Layer:
- Information: Model identity (vendor, family, version), capability boundaries (context window, supported languages), training data characteristics (knowledge cutoff, domain expertise), and behavioral constraints (content policies, safety filters).
- Method: Knowledge probing, capability testing, and response pattern analysis.
RAG:
- Information: Embedding model identity, vector database type, chunking parameters (size, overlap, strategy), retrieval thresholds, and document sources
- Method: Chunk boundary probing, embedding similarity analysis, and source citation extraction.
Agent:
- Information: Available tools and their schemas, permission boundaries, orchestration logic, and error handling behavior
- Method: MCP schema extraction, tool invocation testing, and permission boundary probing
Infrastructure:
- Information: traditional web application information plus AI-specific details: API endpoints, rate limits, error message formats, and backend service identities.
- Method: HTTP header analysis, error message mining, and endpoint enumeration